����������
ؕ�I(xi��n)��Ҫ�Ѓ��c(di��n)1�����Ԍ����e��(j��ng)�W(w��ng)�j(lu��)��(y��ng)��region proposal�IJ��������Ե�����Ӗ(x��n)�������Á�(l��i)��λĿ��(bi��o)��͈D��ָ� 2����(d��ng)��(bi��o)ע��(sh��)��(j��)�DZ��^ϡ��ĕr(sh��)�����������бO(ji��n)���Ĕ�(sh��)��(j��)����Ӗ(x��n)��֮���ض��΄�(w��)�Ĕ�(sh��)��(j��)����fine-tuning���Եõ��^�õ������������Ҳ�����f(shu��)��Imagenet��Ӗ(x��n)���õ�ģ���������Ȼ�����Լ���ҪӖ(x��n)���Ĕ�(sh��)��(j��)��fine-tuningһ����������z�y(c��)Ч���ܺá��F(xi��n)���_(d��)����Ч����Ŀǰ��õ�DPM���� mAP߀Ҫ����20�c(di��n)��Ŀǰvoc��������á�
��ƪ������Ҫ�ǽ�BRCNN�������������������F(xi��n)ast RCNN��Faster RCNN���^�P(gu��n)(li��n)���@ƪ�����Ǻ�ɂ�(g��)�Ļ��A(ch��)
1.��B
���_(k��i)ʼ���f(shu��)��LeCun��(du��)���e��(j��ng)�W(w��ng)�j(lu��)�в��õ�SGD��ͨ�^(gu��)����������S�C(j��)�ݶ��½��㷨����(du��)�W(w��ng)�j(lu��)Ӗ(x��n)������Ч���Ҳֱ�Ӵ��M(j��n)������CNN��(l��i)���z�y(c��)�������
�䌍(sh��)CNN���㷨��90������ѽ�(j��ng)���F(xi��n)�ˣ���ϧ��(d��ng)�r(sh��)��SVMȡ���������Ҫԭ����Ǯ�(d��ng)�r(sh��)Ӗ(x��n)������(d��ng)������2012��ĕr(sh��)��Krizhevsky��(f��)ȼ��CNN������Imagenet�Ĕ�(sh��)��(j��)����Ӗ(x��n)���_(d��)���˷dz��õ�Ч������Ҫ������LeCun�е�һЩ�����磨rectifying non-linearities and ��dropout�� regularization��
���(l��i)������ӑՓ�f(shu��)��CNN����Ŀ��(bi��o)�z�y(c��)�����_(d��)��ʲô�ӵ�Ч��������RossGirshick�ц�(w��n)�}��Ҫ�ۼ�����2��(g��)�c(di��n)�ϣ�
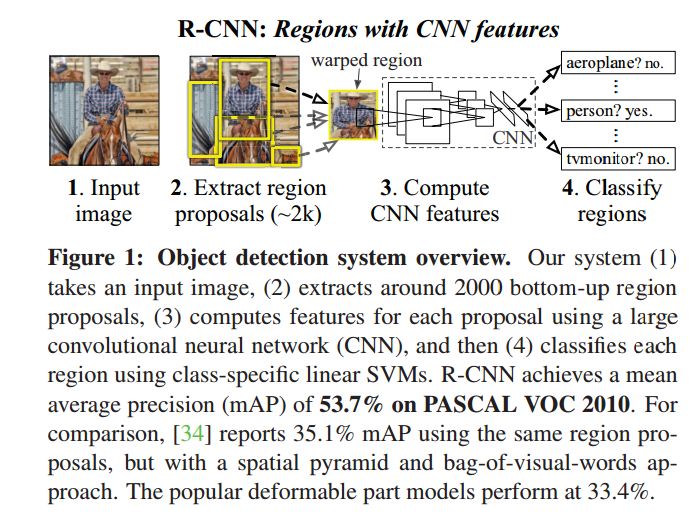
1һ��(g��)������ȾW(w��ng)�j(lu��)��(l��i)��һ��(g��)�z�y(c��)�������������(g��)high-capacity model�����^�ٵĘ�(bi��o)ע��(sh��)��(j��)��(l��i)training��������f(w��n)���D�����������Imagenet������ǧ�f(w��n)�ĈD��(sh��)��(j��)��������D����(l��i)�΄�(w��)�������z�y(c��)����Ҫ��λ�����������RCNN����@��(g��)��λ�D(zhu��n)�Q��һ��(g��)regression problem�����ؚw��(w��n)�}���������(d��ng)Ȼ����?c��)ڮ?d��ng)�r(sh��)Ҳ������(j��ng)���Ҳ����sliding window����ھ��e���������^��ĸ���Ұ���������������](m��i)�в��������?y��n)�֮ǰ��DPM��Ҳ�ѽ�(j��ng)�������@�N����������o(w��)Ч�IJ���̫�ࣨPS.�@�����҂�(g��)�˸��X(ju��)�������ҕ�(hu��)���ӏ�(f��)�s�ȣ�����������������õ���Recognition using region�IJ��ԣ��@�Nparadigm�ѽ�(j��ng)��Ŀ��(bi��o)�R(sh��)�e��semantic segmention��ȡ�����^�õijɹ������ڜy(c��)ԇ�A��������������ȡ�s2000K�A(y��)�x��������A(y��)�x����ͨ�^(gu��)CNN��ȡ��fixed-length����������������ͨ�^(gu��)�ض��(l��i)�e��SVM��(l��i)���(l��i)���������(du��)�ڲ�ͬ��С��ROI�����ˣ�affine image warping����(l��i)�{(di��o)�����̶���size���@�N�����Dz����]region���Π�ġ�����(g��)ϵ�y(t��ng)��overview
2.�ڌ�(sh��)�H�z�y(c��)�У�Ӗ(x��n)���Ęӱ��϶���scarce��������Ӗ(x��n)��һ��(g��)���͵�CNN�W(w��ng)�j(lu��)�������Q�@��(g��)��(w��n)�}�ķ����ǣ�����ͨ�^(gu��)�o(w��)�O(ji��n)�����A(y��)Ӗ(x��n)��unsupervised pretraining,Ȼ�����M(j��n)��supervised training���ڌ�(sh��)�(y��n)�������ᵽ��(j��ng)�^(gu��)fine-tuninig�������z�y(c��)��mAP��8��(g��)�c(di��n)���������Ross�ᵽDonahue��ͬ�r(sh��)�ڵĹ�������ֱ������krizhevsky��CNN�W(w��ng)�j(lu��)�Á�(l��i)��һ��(g��)blackbox feature��extractor���@Ҳ���R(sh��)�e�΄�(w��)�б��F(xi��n)�����^�õ�������������(ch��ng)���R(sh��)�e����(x��)���ȵ��ӷ��(l��i)���I(l��ng)���m��(y��ng)���������(l��i)Ӌ(j��)����ֻ������(g��)�ķ��(l��i)����ֻ��һ��(g��)�����˺ͷǘO��ֵ�������
���e(cu��)�`���������������l(f��)�F(xi��n)bounding box��regression �������@�Ĝp��mislocalization��ͬ���������f(shu��)��?y��n)�RCNN�ǹ�����Region�ϵ������������Ҳ�����^�õđ�(y��ng)�õ�semantic segmentation������Ҳ��voc2011��ȡ�����^�õ�Ч����������õĸ߳�1��(g��)�c(di��n)���������PS.���J(r��n)�鑪(y��ng)ԓ��(hu��)�и��õ����ܣ���(y��ng)ԓ߀�](m��i)������ԭ��(l��i)����Щ�ָ���Ȼ��ه(l��i)�\�ӵ�������
������ȡ���ھW(w��ng)�j(lu��)֮ǰ���ROI���ܴ�С�Π���s�ŵ�һ��(g��)�̶��ijߴ����m��(y��ng)�W(w��ng)�j(lu��)���
2.2
�y(c��)ԇ�r(sh��)�z�y(c��)
��RCNN�������ÿһ�(l��i)��Ӗ(x��n)����һ��(g��)SVM��������(j��)ݔ���������(l��i)�Д࣬ÿһ��(g��)�^(q��)����һ��(g��)�÷�������ͨ�^(gu��)greedy non-maximun supperssinon(for each class independently)��(l��i)���ܻ��߾ܽ^һ��(g��)region��������Ҫ�ǿ����@��(g��)��IoU��region�Ƿ�ȌW(xu��)��(x��)�����ֵ�и��ߵĵ÷����
��(du��)���\(y��n)���
1.���е�CNN����(sh��)���ڸ���(g��)�(l��i)�e���텢��(sh��)
2.CNNӋ(j��)�����(l��i)�ą���(sh��)��low dimensional �;S������c��������������(l��i)����g���������Լ�ҕ�X(ju��)�~��ģ��
-
The only class-specific computations are dot products between features and SVM weights and non-maximum suppression
4.RCNN���ԑ�(y��ng)���(l��i)�e�ܶ���r���Ҳ���Ҫ����һЩ�~��Ľ����ֶ���������ϣʲô������e�ķ������(l��i)�e���L(zh��ng)�r(sh��)�����������(g��)��(f��)�s�ȕ�(hu��)�����ܶ�������֮ǰ��DPM�ķ���ҲҪ�úܶ�
2.3 Ӗ(x��n)���^(gu��)��
supervised-pretraining ----> domain-specifi fine-tuning ---->object categroy classier
1.supervised-pretraining����imagenet��Ӗ(x��n)���õ�ģ��
2.domian-specific fine-tuning ������Ҫ���(l��i)�e��(sh��)Ŀ����������������Ross��IoU��GT����0.5�Ŀ��������ӱ������SGD�� lr��pre-training rate��ʮ��֮һ��0.001���@�Ӳ���(hu��)Ӱ��A(y��)Ӗ(x��n)�����������SGD���������ÿһ�ε�������mini-batch��С��128��������32��(g��)postive window�������96��(g��)negtive window.`
3��ҕ���W(xu��)��(x��)������
�ڿ�ҕ���W(xu��)��(x��)��������������������һ��(g��)�ܴ�ľֲ�����Ұ�Ĕ�(sh��)��(j��)�����@����Ҫ��(du��)�������M(j��n)�п�ҕ���������ݔ��region�D���������(j��)unit����֮�Ĵ�С����(l��i)������(du��)ʲô�ӵ�ݔ������������D���Կ�����һЩUnit��(du��)��Ę������1����һЩ��(du��)�c(di��n)����������������2���������������������(du��)�tɫ���У���(du��)�����Ќ�(du��)��������������Ҳ�܌�һЩ�����ںϵ�һ�����ɫ��������y�����Π��������5�е����ӡ������ȵ�
3.2 �P(gu��n)�څ���(sh��)�������о�
1.performace�](m��i)��fine-tuning
�ı��п��Կ���fc7�a(ch��n)����������f(w��n)c6�ɫ�������Ҫ�������@Ҳ�����f(shu��)29%���1.68million��(g��)��(sh��)��(j��)�ǿ��ԏ�CNN�W(w��ng)�j(lu��)��ȥ��������������?gu��)��?du��)mAP�](m��i)ʲôӰ���������@Ӡ���������������f6��f7��ȥ����Ԓ(hu��)��ֻ��pool5�ӵą���(sh��)Ҳ���Ǵ�������(g��)�W(w��ng)�j(lu��)6%�ą���(sh��)Ҳ����ȡ�ò��e(cu��)�ĽY(ji��)�����D��ʾ�����Կ�����representational��������Ҫ�ǁ�(l��i)����CNN�ľ��e��������������Ҫ��ȫ�B�ӌ�����@��(g��)�l(f��)�F(xi��n)�������ڳ��ܵ�����map�У������f(shu��)Hog�����@�N���F(xi��n)����Ҳ�����f(shu��)�҂��п��Ԍ��䑪(y��ng)�õ�һЩ����(d��ng)���z�y(c��)������DPM��������pool5���������A(ch��)֮�ϡ�����ԭ�ģ�Much of the CNN��s representationalpower comes from its convolutional layers, rather than fromthe much larger densely connected layers. This finding suggests potential utility in computing a dense feature map, in the sense of HOG, of an arbitrary-sized image by using only the convolutional layers of the CNN. This representation would enable experimentation with sliding-window detectors, including DPM, on top of pool5 features��
2.��(j��ng)�^(gu��)fine-tuning������
���Կ���fine-tuning��Ч��߀�Ǻ����@�ģ��������8��(g��)�c(di��n)�������Ҍ�(du��)��fc67��Ч�������@�����@Ҳ�����f(shu��)��imagenet�ЌW(xu��)��(x��)����pool5���������^general������Ҍ�(du��)�����ܵ�������Ҫ�ǁ�(l��i)�Ԍ�(du��)�����������A(ch��)�ϵ�domain-specific���w��(y��ng)�È�(ch��ng)����non-linear���(l��i)����Ӗ(x��n)������
3.4 �P(gu��n)��BBOX
������Ҫ���_����������RCNN�����Ǐ��A(y��)�x�����x��һ��(g��)�Д�һ����ô��(ji��n)��������Փ���е��e(cu��)�`��������ֵęz�y(c��)�e(cu��)�`����Ҫ�ɷֶ���localize error Ҳ���Ƕ�λ�e(cu��)�`������IoU��0.1��0.5֮�g���c�e���(l��i)�e�Լ�����confusion�����dz�С�����@�����߸���(j��)���ݔ����feature �M(j��n)һ������regression����� ���õ���֮ǰ��DPM�z�y(c��)�е��õ�Linear regression model���@��(g��)mAP��������4��(g��)�c(di��n)��
4 Semantic segmentation
����Ҳ�ᵽ�ˌ�RCNN�W(w��ng)�j(lu��)���Z(y��)�ָ�����������Ч���cĿǰ�^�õ�O2P�ķ����](m��i)�б��|(zh��)����s0.9�����J(r��n)����Ҫ߀�ǾW(w��ng)�j(lu��)�W(xu��)��(x��)�^(gu��)�̲����㣬�䌦(du��)�ڼ�(x��)���ȵ������](m��i)��һ��(g��)���w�ČW(xu��)��(x��)�^(gu��)�̣�Ŀǰ��semantic segmentation��������õ��ǡ�Learning Deconvolution Network for Semantic Segmentation��Ŀǰ��pascal-voc��(sh��)��(j��)�����ǵ�һ�����ܣ����ľW(w��ng)�j(lu��)����һ��(g��)��(du��)�Q(ch��ng)��deconvolutoin network���
�Y(ji��)���Z(y��)������@����_��(sh��)�������Ŀ��(bi��o)��z�y(c��)����������ͣ����ǰ���������F(xi��n)����õ�DPM�㷨���ǽY(ji��)�Ϻö�l(xi��ng)ow-level��feature�������@Щfeature�����ֹ��O(sh��)Ӌ(j��)�ļ���һЩhigh-level context from detector��scene classifier���@ƪ���½o���˻���Region proposal��CNN�W(w��ng)�j(lu��)�O��������mAP�������бO(ji��n)�����A(y��)Ӗ(x��n)�����ض���(ch��ng)�ϵ�fine-tuning�@һģʽ��(hu��)ᘌ�(du��)�ܶ���(sh��)��(j��)ϵϡ�����ҕ�X(ju��)��(w��n)�}��Ч���������@�����˼���f(shu��)��Imagenet��Ӗ(x��n)���õ��ǂ�(g��)ģ�ͣ�Ȼ�����(j��)�Լ����ض���(y��ng)�È�(ch��ng)������ģ�����Լ��Ĕ�(sh��)��(j��)fine-tuningһ���������@�ӵ�������ͦ��Ч�����
|