�����W(xu��)��(x��)��˼��Դ���О�����W(xu��)��behavioural psychology�����о���1911��Thorndike�����Ч�÷��t��Law of Effect����һ���龳������е�������О飬�͕��c���龰�ӏ�(li��n)ϵ�������龰�٬F(xi��n)�r��������@�N�О�Ҳ�����٬F(xi��n)���෴��������X��������О飬���p���c���龰��(li��n)ϵ�����龰�٬F(xi��n)�r�����О錢���y�٬F(xi��n)���Q��Ԓ�f���ǷN�О����ӛסȡ�Q��ԓ�О�a(ch��n)����Ч�á����磺�������ӳ��w�P�r��������w�P�o���˵��О�@��������^������ʹ�á�������ӳ����w�P���@���О�͡������ӳ��w�P�r���@���龰�ӏ���(li��n)ϵ�����@������^����Ч�Ì�ʹ��ӛס������ӳ����w�P�����О顣
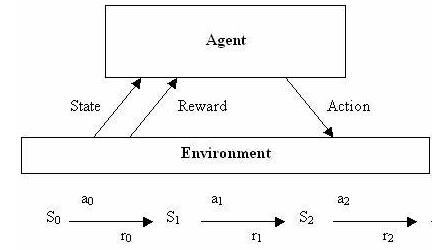
�ڽo���龳�£��õ�������О���������������ܵ����P���О���������������@��һ�N��������ģʽʹ�Ä�����ԏIJ�ͬ�О�Lԇ�@�õĪ������P�W(xu��)����ԓ�龳���x��Ӗ(x��n)�������������О顣�@���Ǐ����W(xu��)��(x��)�ĺ��ęC�ƣ���ԇ�e��trail-and-error����W(xu��)���ڽo�����龳���x����ǡ��?sh��)��О顣Sutton���x�����W(xu��)��(x��)�飺ͨ�^ԇ�e�W(xu��)��(x��)�����ѵ�ƥ���B(t��i)��states���̈́�����actions�������ګ@�����Ļ؈�rewards����
�����W(xu��)��(x��)���Hֱ��ģ��������W(xu��)��(x��)������ģʽ������Ҳ�������������(sh��)�C���W(xu��)��(x��)�����У������w��Ҫ�����Vȥ�x���ķN������ʹ�Ï����W(xu��)��(x��)�����������w�܉�ͨ�^�Lԇ��ͬ�Ą����������ذl(f��)�F(xi��n)���x��a(ch��n)�����؈�Ą���������Tesauro���������ǘӣ������W(xu��)��(x��)ʹ�������w���Ը���(j��)�Լ��Ľ�(j��ng)��M�������،W(xu��)��(x��)���Ȳ���Ҫ�κ��A(y��)��֪�RҲ����ه�κ��ⲿ���ܡ��ώ����Ď�����
�����W(xu��)��(x��)���X
�������ѵ�ƥ���B(t��i)�̈́������������W(xu��)��(x��)����Q���@�Ӻܾ����ձ��ԵĆ��}��ʹ�Ï����W(xu��)��(x��)�ڙC���ˌW(xu��)���(y��u)���ƣ�����ģ����Բ��ģ��w�п��ƣ���(d��o)���ƌ�(d��o)���A(y��)�y�Q�ߣ�����Ͷ�Y�Լ����н�ͨ���Ƶ��I(l��ng)���д����đ�(y��ng)�á�
�ُ�Ӌ��C���F(xi��n)�ĽǶȿ��������(sh��)�����C���W(xu��)��(x��)�ķ�������Ҫ���F(xi��n)�����w��������֪��Ҫ�����w��Q�Ć��}�ǡ�ʲô�����Լ����}����ô�ӡ�����Q����ͨ�^����ָ������V�����w�����⡣�z�����ǣ�֪������ʲô���h��֪������ô���������ζ�öࡣ���磬�����@��һ�����}��һ�����н�ͨ�W(w��ng)�j(lu��)�ɶ���ʮ��·���Լ�����֮�g�ĵ�·�M�ɣ�ÿһ��ʮ��·�ڵĽ�ͨ����һ��Agent���ƣ���ô�@����Agent��(y��ng)ԓ��΅f(xi��)�����Ƽt�G���ĕr���L�̣�ʹ���M��ԓ���н�ͨ�W(w��ng)�j(lu��)������܇�v����̕r�g��(n��i)�x�_ԓ���н�ͨ�W(w��ng)�j(lu��)�أ�Agent�W(xu��)��(x��)Ҫ����ʲô���Ć��}�������ģ�ʹ����܇�v����̕r�x�_ԓ���н�ͨ�W(w��ng)�j(lu��)���������������s�Ǐ�(f��)�s�����y�ġ�
�����W(xu��)��(x��)�ṩ���@��һ�N���õ�ǰ����ֻҪ�_���˻؈�����ҪҎ(gu��)��Agent��������΄�(w��)��Agent ���܉�ͨ�^ԇ�e�W(xu��)����ѵĿ��Ʋ��ԡ���ǰ��Ķ�Agent��ͨ���Ɔ��}�У�ֻ��Ҏ(gu��)������܇�vͨ�^�r�gԽ�̫@ȡ�Ļ؈�Խ����ô�@����Agent�������W(xu��)���(y��u)�Ľ�ͨ��f(xi��)�����Ʋ���ʹ������܇�v����̕r�g��(n��i)ͨ�^ԓ���оW(w��ng)�j(lu��)���M��ֱ�����죬��Q�@�Ӷ���ʮ��·�ڵĽ�ͨ�����Ɔ��}�������W(xu��)��(x��)��Ȼ���R���Ӌ�������^�L��Ӌ��r�g�����Č��F(xi��n)�ĽǶȁ����������J�鏊���W(xu��)��(x��)��һ�N�����ˏı�횿��]����ô�����н�ų����ęC���W(xu��)��(x��)������Ҳ���ŏ����W(xu��)��(x��)���܉�ʹ�������܉����Bezdek�����ď�Ӌ�������M�����˹�����ֱ���������ܵ�;��֮һ��
�����W(xu��)��(x��)ʾ��
�����W(xu��)��(x��)���о��vʷ��1954��Minsky�״�������������͡������W(xu��)��(x��)���ĸ�����g(sh��)�Z��1965���ڿ�����Փ��Waltz�����OҲ����@һ�������ͨ�^���͵��ֶ��M�ЌW(xu��)��(x��)�Ļ���˼�롣���������_�ˡ�ԇ�e���Ǐ����W(xu��)��(x��)�ĺ��ęC�ơ�Bellman��1957�����������(y��u)���Ɔ��}�Լ��(y��u)���Ɔ��}���S�C�xɢ�汾�R���ɷ�Q���^�̣�Markov Decision Process��MDP���ĄӑB(t��i)Ҏ(gu��)����Dynamic Programming����������ԓ����������������Ə����W(xu��)��(x��)ԇ�e�������ęC�ơ��M����ֻ�Dz����ˏ����W(xu��)��(x��)��˼������R���ɷ�Q���^�̣������υs��(d��o)�����R���ɷ�Q���^�̳ɞ鶨�x�����W(xu��)��(x��)���}�����ձ���ʽ�������䷽���ĬF(xi��n)�������ԣ����º���ĺܶ��о��߶��J�鏊���W(xu��)��(x��)��Դ��Bellman�ĄӑB(t��i)Ҏ(gu��)�����S��Howard���������R���ɷ�Q���^�̵IJ��Ե���������
���˕r�����W(xu��)��(x��)����Փ���A(ch��)���R���ɷ�Q���^�̣�������㷨:ԇ�e�IJ��Ե��������_�������˺�һ�Εr�g�������W(xu��)��(x��)���O(ji��n)���W(xu��)��(x��)��supervised learning���Ĺ�â�����ڣ���y(t��ng)Ӌģʽ�R�e���˹���(j��ng)�W(w��ng)�j(lu��)�����ڱO(ji��n)���W(xu��)��(x��)���@�N�W(xu��)��(x��)��ͨ�^�ⲿ��֪�R�ıO(ji��n)�����ṩ�����Ӂ��M�ЌW(xu��)��(x��)�ģ����@�N�W(xu��)��(x��)�ѽ�(j��ng)��ȫ�`���ˏ����W(xu��)��(x��)����ּ�����O(ji��n)���W(xu��)��(x��)���ˡ��̎�����supervisor���������A(y��)��֪�R��examples������1989�꣬Watkins�����Q�W(xu��)��(x��)�Mһ����չ�ˏ����W(xu��)��(x��)�đ�(y��ng)�ú�����ˏ����W(xu��)��(x��)��Q�W(xu��)��(x��)ʹ����ȱ�������؈�(sh��)����Ȼ��Ҫ֪����K�؈����Ŀ�ˠ�B(t��i)���͠�B(t��i)�D(zhu��n)�Q����(sh��)��֪�R����Ȼ��������(y��u)�������ԣ��Q��Ԓ�f��Q�W(xu��)��(x��)ʹ�Ï����W(xu��)��(x��)������ه�چ��}ģ�͡�����Watkins߀�C���ˮ�ϵ�y(t��ng)�Ǵ_���Ե��R���ɷ�Q���^�̣����һ؈���������r�£������W(xu��)��(x��)���Ք��ģ�Ҳ��һ����������(y��u)�⡣����Q�W(xu��)��(x��)�ѽ�(j��ng)�ɞ���V��ʹ�õď����W(xu��)��(x��)������
(li��n)ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�W(w��ng)վ��http://www.mat7lab.com/
�W(w��ng)վ��http://www.hslogic.com/
�Œ�һ�ߣ�